I was inspired to give ChatGPT a try after reading a post. The author describes using ChatGPT to code a model.
So I had a conversation with ChatGPT about the social sciences, statistics and R.
I have to say that I am impressed.
ChatGPT and I had an exchange about R. I asked for some examples. ChatGPT originally had a preference for Base-R code but it used more Tidyverse-R approaches after I asked for it. Or it converted the Base-R code to Tidyverse-R at my request.
The code examples were good and I really liked the comments it added to the code. At some point ChatGPT went back to Base-R and I could not fully convince it to use a Tidyverse-R first approach.
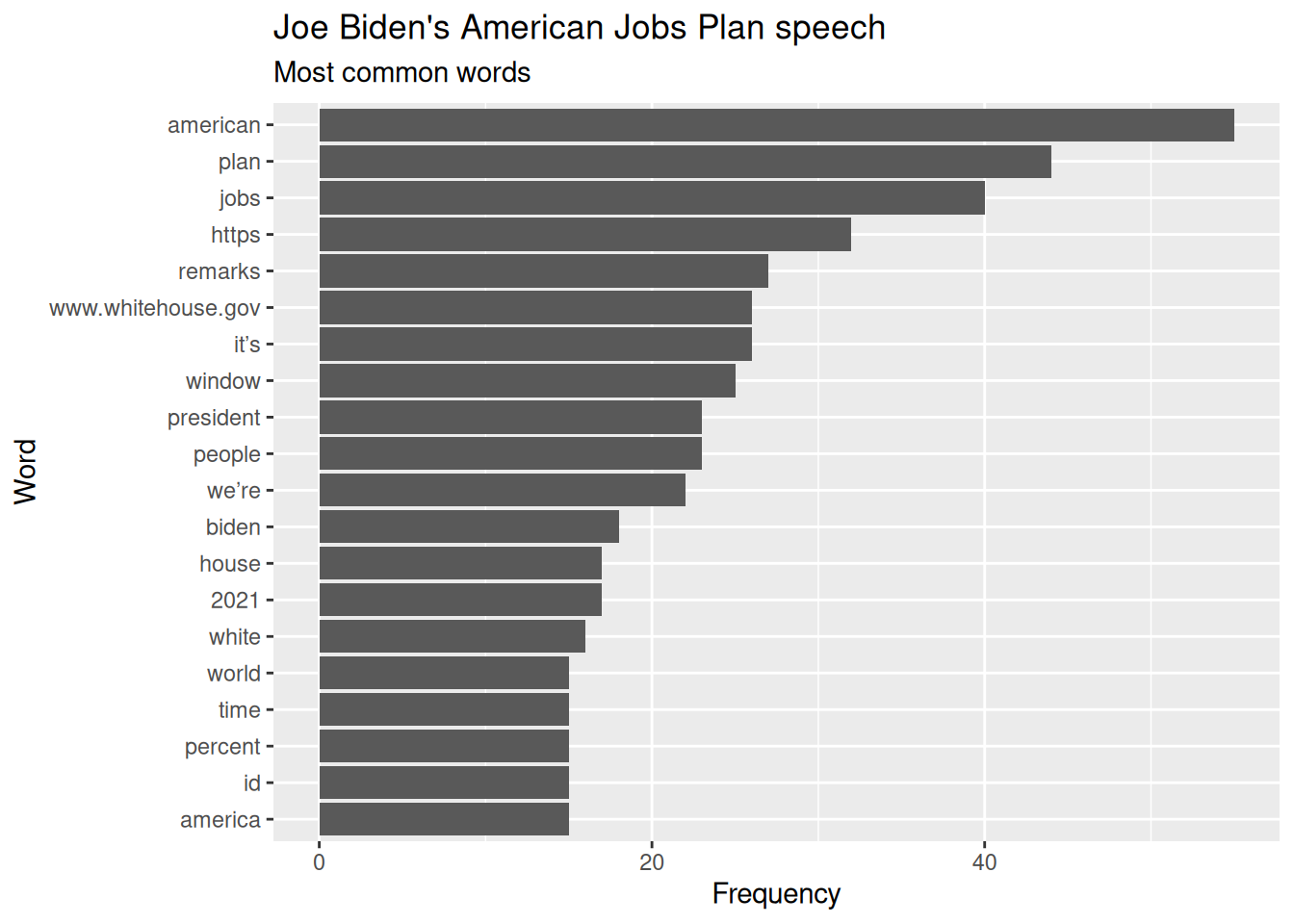
So here is a nice output from our exchange. I asked for a text analysis of a Biden speech in R.
Parts from the content of the exchange are below.
I added the rvest::read_html parts from the ChatGPT suggestion. I did not find a way that ChatGPT added it to its initial script. ChatGPT had some Base-R and Tidyverse-R confusion at this point. I updated the title of the figure to the new speech title used as well.
I don’t use tidytext regularly so looking up the information would have taken some time for me. Here, ChatGPT was very helpful. Thanks.
Code
library(tidyverse)library(tidytext)library(rvest)# Read in the HTML documenthtml_doc <-read_html(paste0("https://www.whitehouse.gov/briefing-room/speeches-remarks/","2021/03/31/remarks-by-president-biden-on-the-american-jobs-plan/"))# Extract the textbiden_speech <-html_text(html_doc)# Tokenize speechbiden_words <- biden_speech %>%enframe(name =NULL, value ="text") %>%unnest_tokens(word, text)# Remove stop wordsbiden_words <- biden_words %>%anti_join(stop_words)# Calculate word frequenciesword_freq <- biden_words %>%count(word, sort =TRUE)# Visualize word frequenciesword_freq %>%top_n(20) %>%ggplot(aes(x = n, y =reorder(word, n))) +geom_col() +labs(x ="Frequency",y ="Word",title ="Joe Biden's American Jobs Plan speech",subtitle ="Most common words" )
Joe Biden’s American Jobs Plan speech
user can we analyse a biden speech?
ChatGPT Yes, we can use text analysis techniques to analyze a speech by Joe Biden. Here’s an example using the tidytext package:
library(tidyverse)library(tidytext)# Load speech databiden_speech <-read_lines("https://www.rev.com/blog/transcripts/joe-biden-covid-speech-transcript-september-9")# Tokenize speechbiden_words <- biden_speech %>%enframe(name =NULL, value ="text") %>%unnest_tokens(word, text)# Remove stop wordsbiden_words <- biden_words %>%anti_join(stop_words)# Calculate word frequenciesword_freq <- biden_words %>%count(word, sort =TRUE)# Visualize word frequenciesword_freq %>%top_n(20) %>%ggplot(aes(x = n, y =reorder(word, n))) +geom_col() +labs(x ="Frequency", y ="Word", title ="Most common words in Joe Biden's COVID speech")
In this example, we load the transcript of a speech by Joe Biden on the topic of COVID-19, which is available as a text file from the Rev.com blog. We tokenize the speech using the unnest_tokens() function, remove stop words using the anti_join() function, and calculate word frequencies using the count() function. Finally, we visualize the most common words using ggplot2. Note that in order to run this code, you will need to have the readr package installed to read in the text file from the web.
user the url does not work
ChatGPT I apologize for that. Here’s an updated example using a different speech by Joe Biden that is available as a text file from the University of Pennsylvania:
library(tidyverse)library(tidytext)# Load speech databiden_speech <-read_lines("https://www.sas.upenn.edu/~jkingsby/BidenIowaSpeech.txt")# Tokenize speechbiden_words <- biden_speech %>%enframe(name =NULL, value ="text") %>%unnest_tokens(word, text)# Remove stop wordsbiden_words <- biden_words %>%anti_join(stop_words)# Calculate word frequenciesword_freq <- biden_words %>%count(word, sort =TRUE)# Visualize word frequenciesword_freq %>%top_n(20) %>%ggplot(aes(x = n, y =reorder(word, n))) +geom_col() +labs(x ="Frequency", y ="Word", title ="Most common words in Joe Biden's Iowa speech")
In this example, we load a different speech by Joe Biden that is available as a text file from the University of Pennsylvania. The rest of the code is the same as in the previous example.
user that url is also not working. do you have a link for a biden speech
ChatGPT I apologize for the inconvenience. Here is a link to a transcript of a recent speech by Joe Biden on infrastructure:
You can copy the text of the speech from this page and use it in the read_lines() function to load it into R for analysis using the tidytext package.
user how can i convert a html document to text in r?
ChatGPT You can use the rvest package in R to extract text from HTML documents. Here’s an example code snippet that shows how to do this:
library(rvest)# Read in the HTML documenthtml_doc <-read_html("https://www.whitehouse.gov/briefing-room/speeches-remarks/2021/03/31/remarks-by-president-biden-on-the-american-jobs-plan/")# Extract the texttext <-html_text(html_doc)# Print the textcat(text)
In this example, we use the read_html() function from rvest to read in the HTML document from the provided URL. We then use the html_text() function to extract the text from the HTML document. Finally, we use cat() to print the text to the console.
Note that the rvest package is designed for web scraping, so it is important to respect the terms of use and not use it to scrape websites without permission.
user ok, can you add that to the r code snippet above?